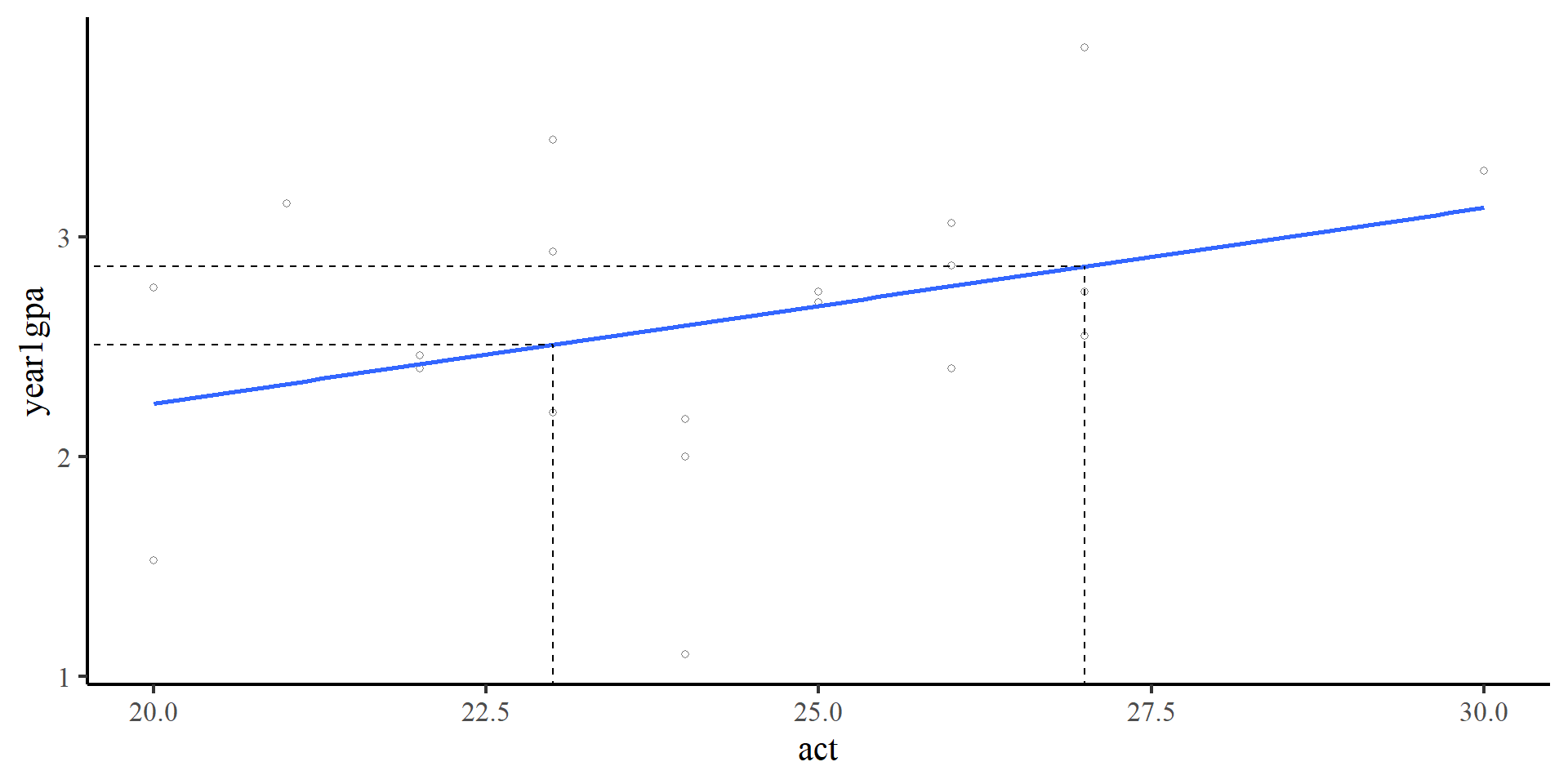
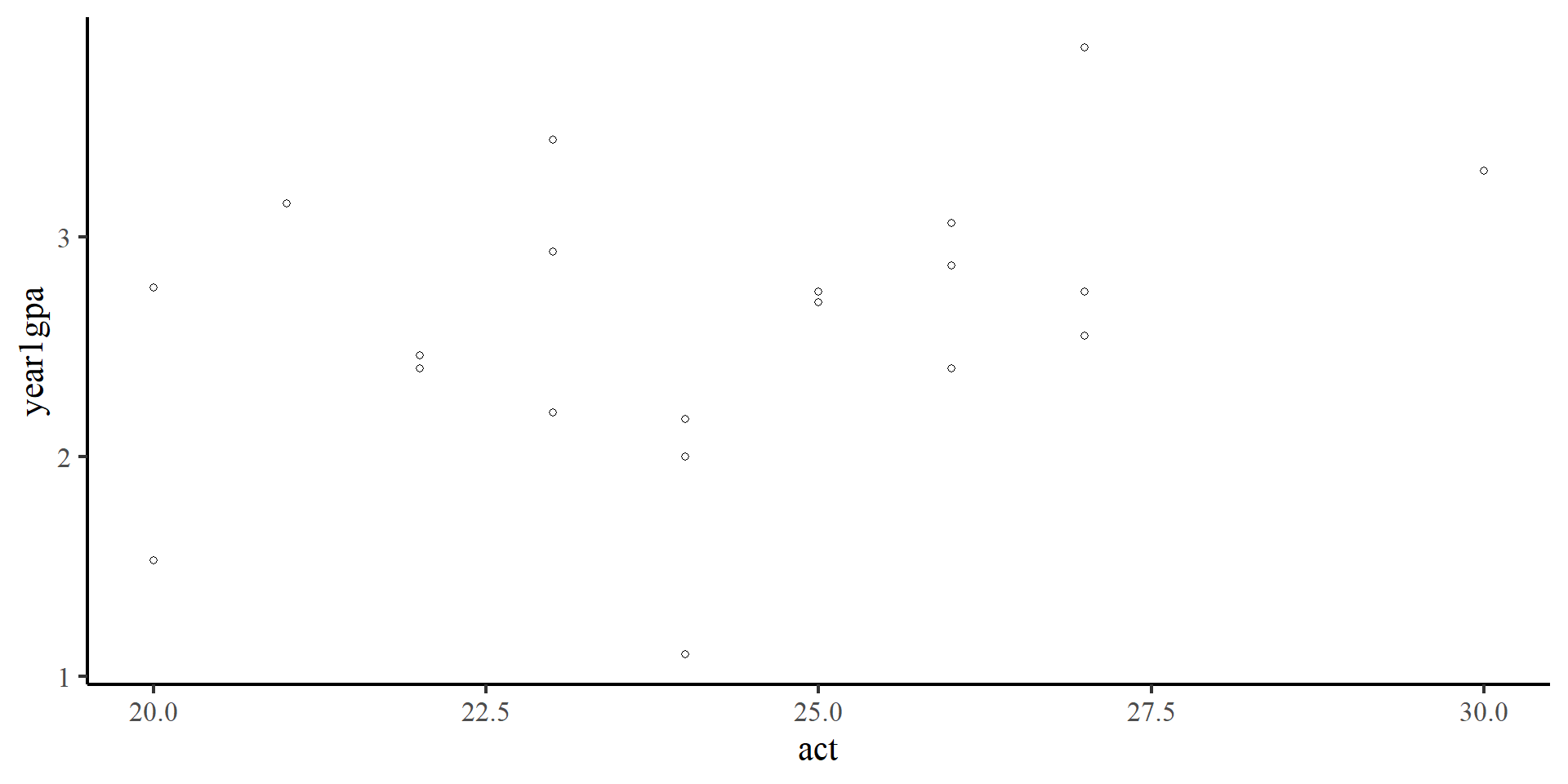
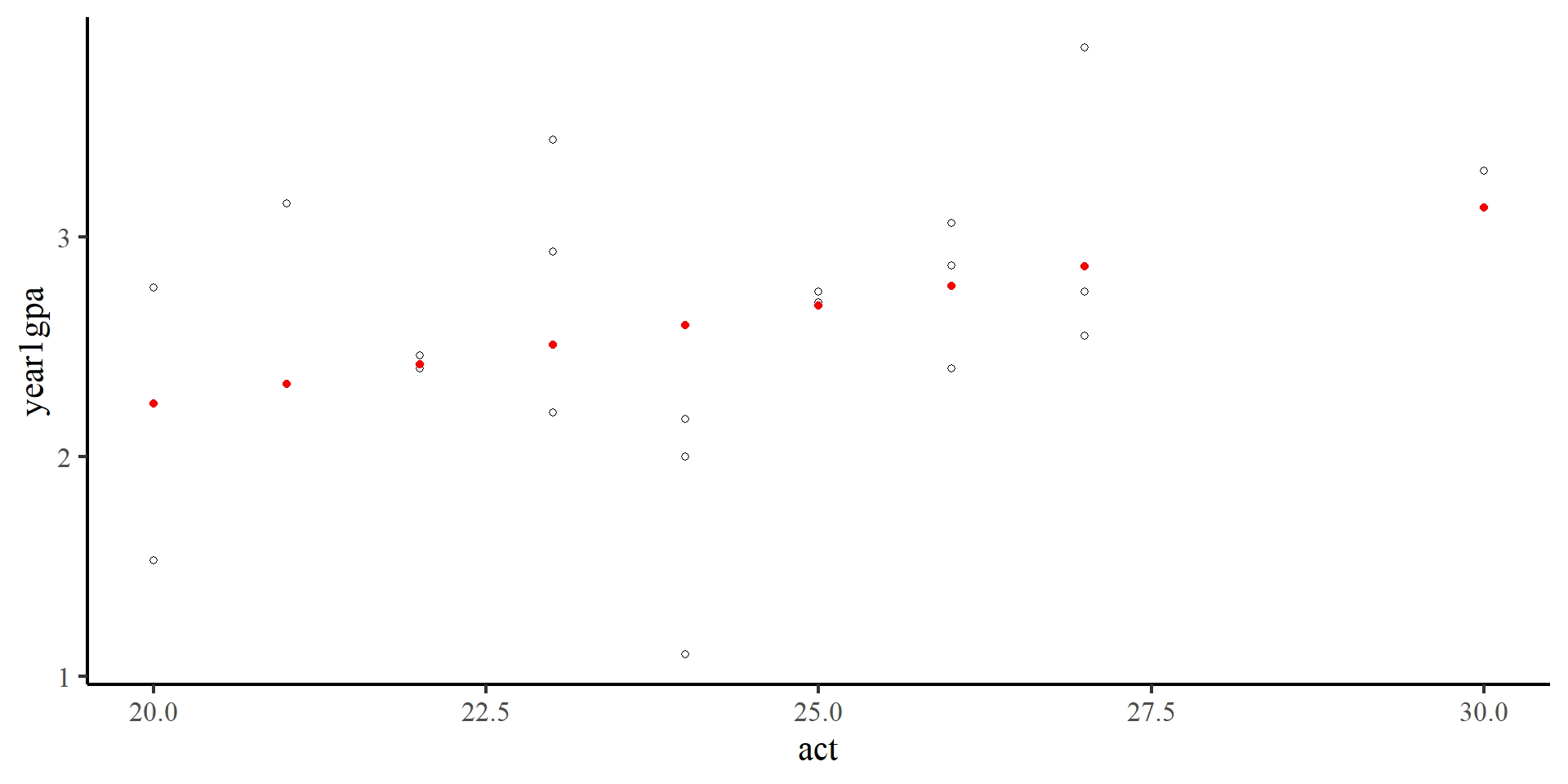
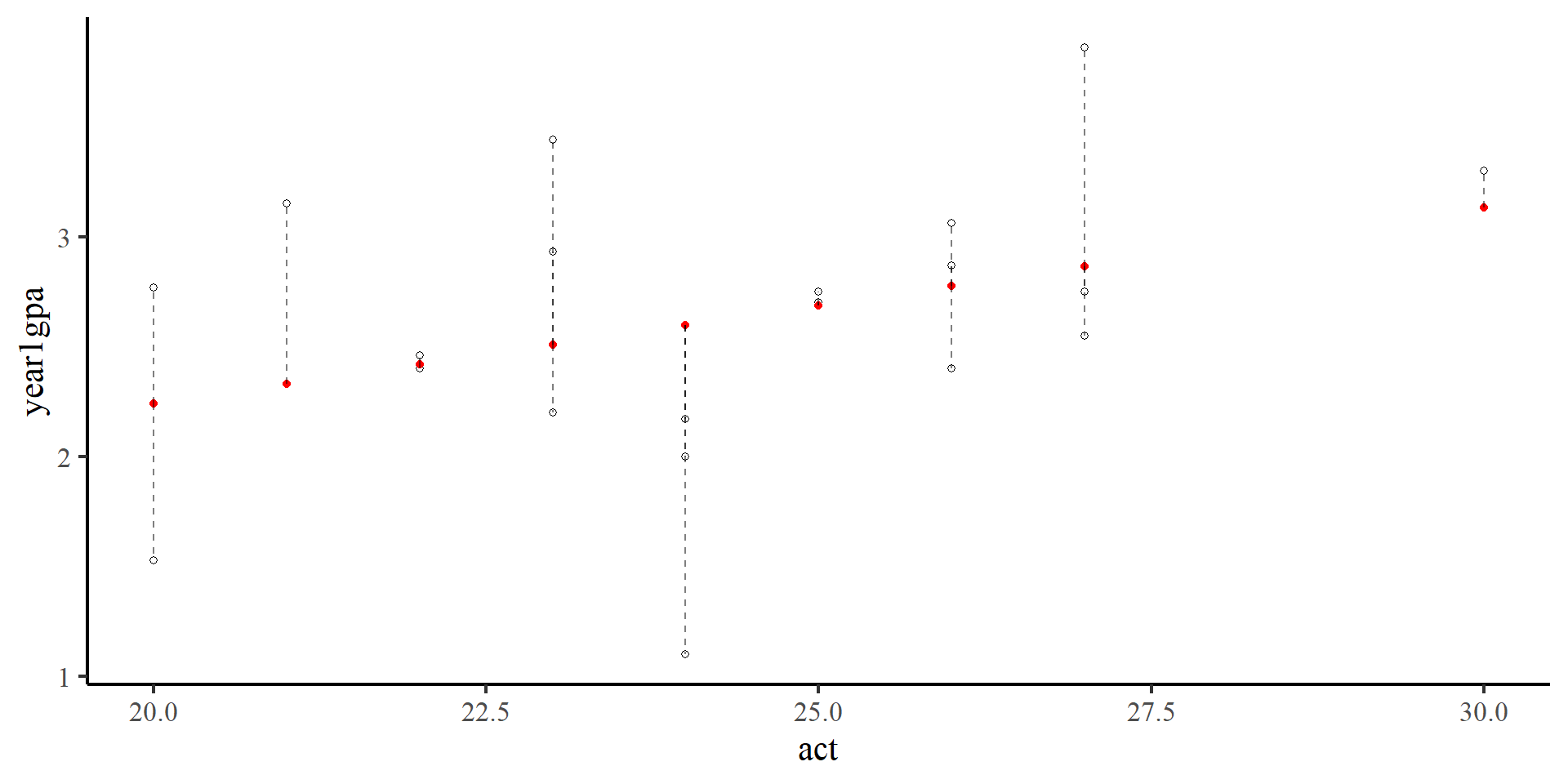
Fox, J., Weisberg, S., Price, B., Adler, D., Bates, D., Baud-Bovy, G., Bolker, B., Ellison, S., Firth, D., Friendly, M., Gorjanc, G., Graves, S., Heiberger, R., Krivitsky, P., Laboissiere, R., Maechler, M., Monette, G., Murdoch, D., Nilsson, H., … R-Core. (2024).
Car: Companion to Applied Regression (Version 3.1-3) [Computer software].
https://cran.r-project.org/web/packages/car/index.html
Revelle, W. (2024).
Psych: Procedures for Psychological, Psychometric, and Personality Research (Version 2.4.6.26) [Computer software].
https://cran.r-project.org/web/packages/psych/index.html
Wickham, H., & RStudio. (2023).
Tidyverse: Easily Install and Load the ’Tidyverse’ (Version 2.0.0) [Computer software].
https://cran.r-project.org/web/packages/tidyverse/index.html